[ICLR2021] (ViT) An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
ICLR2021
Link: [2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
Code: lucidrains/vit-pytorch: Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch (github.com)
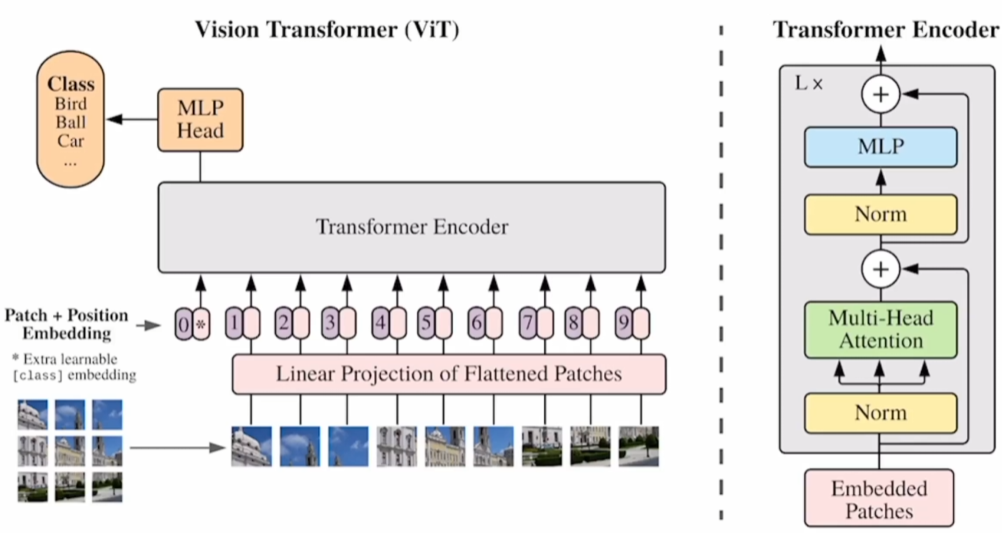
1 Method
1.1 图像预处理
1.1.1 原始输入(Input)
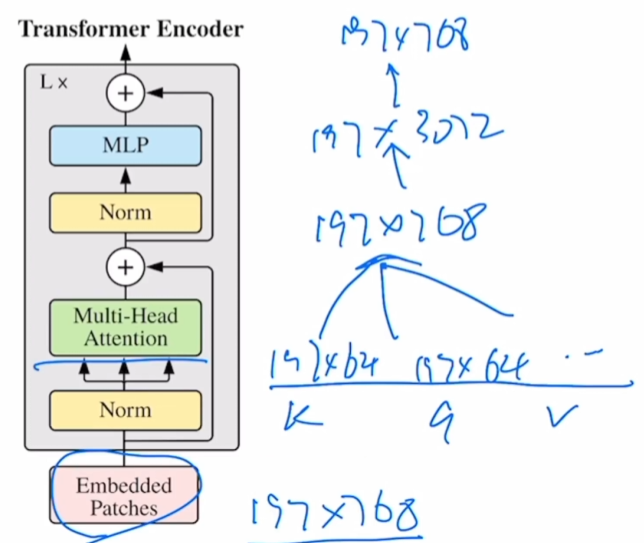
输入图像尺寸224 x 224 x 3,patch size为16 x 16,
那么模型输入为(224/16)^2 x (16 x 16 x 3) = 196 x 768(N x D)
即196个patch,每个patch拉直后维度是768
1.1.2 Linear Projection(E)
Patch首先经过一个FC,大小是768→768
FC输入维度196 x 768→FC输出维度196 x 768
1.1.3 Extra CLS Embedding
额外加入一个CLS Embedding,大小为1 x 768
1.1.4 Position Embedding
加入位置信息,也是一个矩阵,大小为 N x D,即197 x 768
learnable
将Position Embedding直接加到patch embedding和 CLS embedding上
(注意:是sum,不是concat)
1.2 Transformer Encoder
Transformer Encoder由L个Transformer Block组成
1.2.1 Embedded Patches
Embedded Patches (197 x 768)
= Patch Embedding (196 x 768)
+(concat) CLS Embedding (1 x 768)
+(add) Position Embedding (197 x 768)
Encoder输入尺寸:(196+1) x 768 = 197 x 768
1.2.2 Multihead Attention
在base版本中,有12个head,那么每一个head的K、Q、V维度为197 x (768/12)=197 x 64
再将每一个head的结果重新concat起来拼成197 x 768
1.2.3 MLP
先放大,再缩小维度
197 x 768→197 x 3072→197 x 768
1.3 Encoder’s Output
将CLS Embedding的输出作为整个Transformer Encoder的输出,即整张图像的特征
1.4 Overview
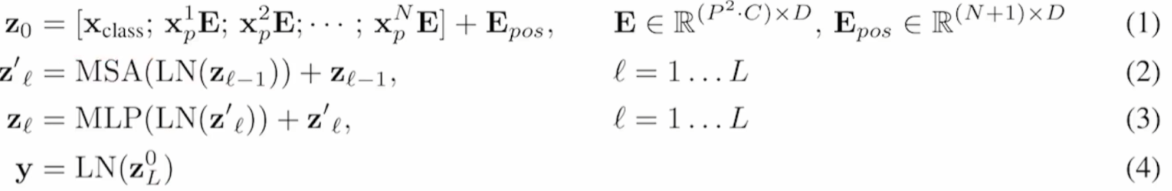
2 Ablation
2.1 [class] token (CLS Embedding)
[class] token v.s. GAP(Global Average Pooling)
在VIT中,使用[class] token的输出作为整张图像的特征
在CNN中,是在最后的feature map上做GAP(Global Average Pooling)作为图像特征
那为什么VIT不也在所有的patch的输出上使用GAP呢,经过消融实验,二者效果差不多,为了跟原始Transformer一致,继续使用的[class] token的输出作为整张图像的特征
实验结论:效果差不多
2.2 Position Embedding
None:不加位置编码,想象为 bag of patch
1d:跟原始Transformer一样
2d:更加符合图像的特征,两个D/2维的向量分别表示 x 和 y 方向,然后concat在一起拼回D维度向量
相对位置编码:使用相对位置进行编码
实验结果
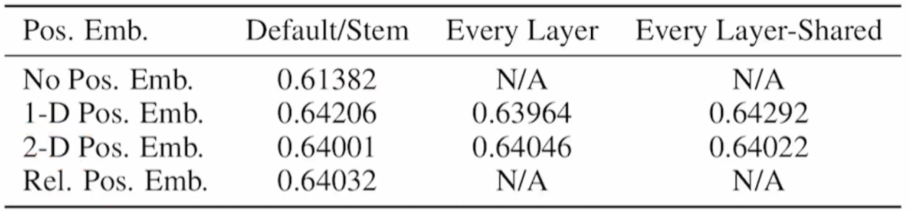
结论:效果差不多
3 Experiment
3.1 参数量
3.2 分类实验结果
刷榜
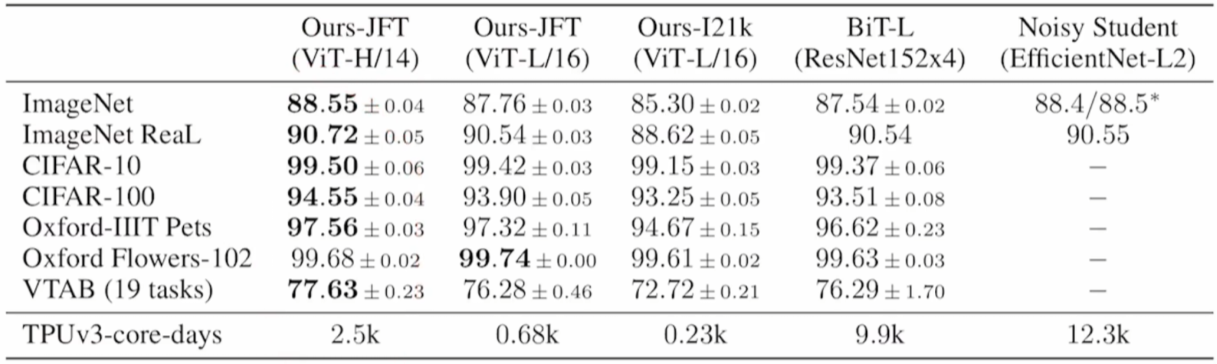
3.3 在不同规模的数据集上预训练
结论:
在小数据集上(ImageNet)上进行预训练,效果不如BiT ResNet;
在大数据集上(JFT-300M)上进行预训练,效果比ResNet好。
想使用ViT,那么至少需要准备规模与ImageNet-21k相当的数据集,否则还是CNN效果更好
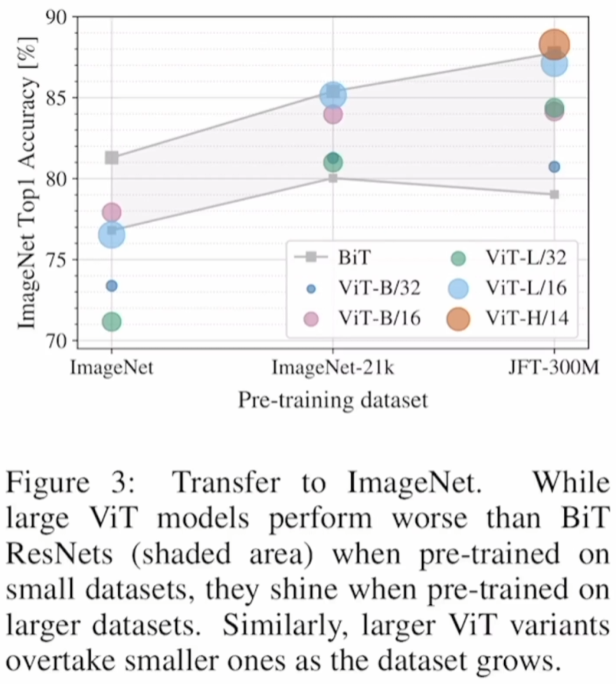
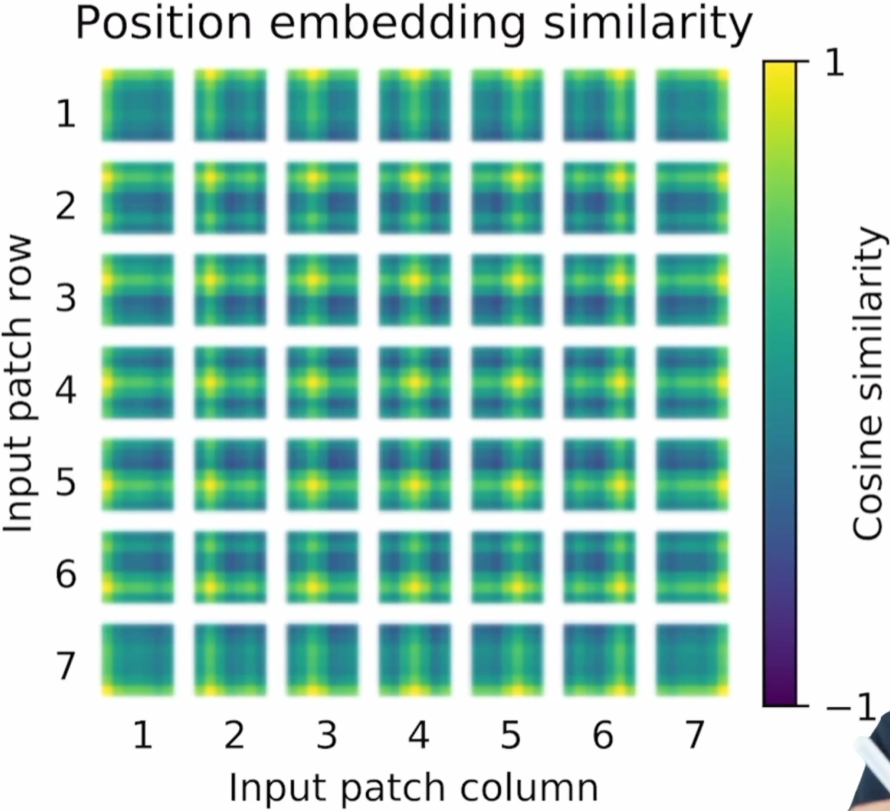
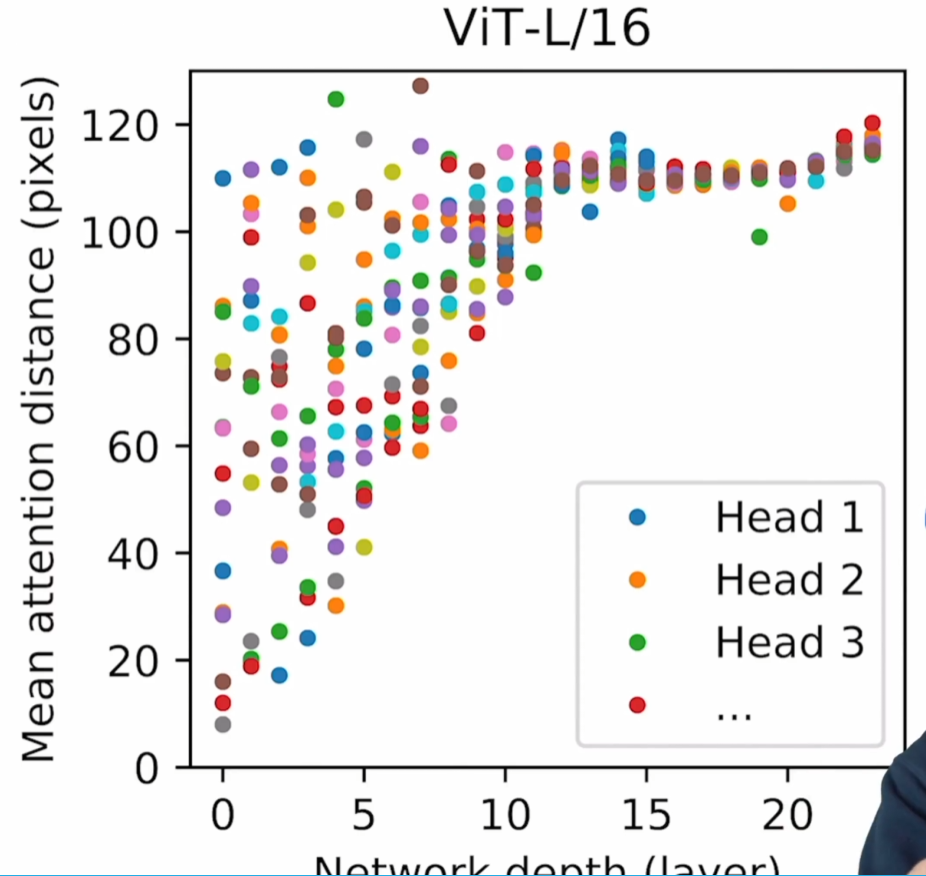
3.4 Embedding Filter, Position Embedding & Attention Distance
(左图)**Embedding Filter(E)**的结果,可以看到跟CNN差不多,提取到了纹理、颜色等信息
(中图)Position Embedding Similarity:虽然是1d位置编码,但是还是学到了2d的位置信息,也可以解释为什么换成2d的位置编码后并没有什么结果的提升
(右图)Mean Attention Distance:每一个head能注意到多远的距离(可以理解成感受野?),在浅层网络时有的只能注意到很近的距离,但有的已经可以注意到很远的距离了;随着网络的深入,每一个head都可以注意到很远的距离了 //
//  //
// 
3.5 Self-Supervision
仿照BERT,进行masked patch prediction
结果:ViT-B/16在Imagenet上达到79.9% acc,比有监督低4%
(挖坑)